

Exploring Washington State’s Voter Turnout with Machine Learning 2024








Research Question:
Can an accurate predictive Machine Learning Model be developed from the data?
Null Hypothesis H0:
The distribution of voter engagement is random.
Alternative Hypothesis H1:
The distribution of voter engagement is not random.
Context:
The contribution of this study to the field of Data Analytics and voter awareness is to create a Random Forrest machine learning model to predict voter turnout in Washington State elections. With this information voters and policymakers can obtain situational awareness and possible courses of action.
An article titled, Using Machine Learning for Voting Anomaly Detection, showcases a study using a Radom Forrest to explore voter engagement strength using the identical variables of ‘Year’, ‘Turn Out’, and ‘Election Types’ (NIH, 2019).
They found that these variables are key factors in overall voter turnout and understanding.
The Random Forrest is an ensemble of decision trees that are reduced down to a single vote; Like a common democratic voting system (IBM, 2022). Understanding these variables can help describe the relationship between the Independent Variables and Dependent Variables.
Data:
An open-source dataset of Wasington State data containing the necessary variables about voter engagement. The Washington Secretary of State is the open-source repository / organization that hosts the datasets. The dataset contains almost 73 rows (before any rows where removed) and 7 columns. The dataset is limited to only 16 years of elections; Spanning from 2007 – 2023. The dataset has multiple columns for possible exploration. Different voters participate based on numerous exogenous factors. Delimitations for this analysis, while more data was available for previous years earlier than 2007, the variables did not contain voter turnout %.
The original columns used are: 'Date', 'Election_Type', 'Counties', 'Precincts', 'Registered_Voters', 'Total_Ballots_Counted', 'TurnOut%'.
The columns generated after cleaning are: 'Date', 'Counties', 'Precincts', 'Registered_Voters', 'Total_Ballots_Counted', 'TurnOut%', 'Election_Type_February Special Election', 'Election_Type_General Election', 'Election_Type_March Special Election', 'Election_Type_May Special Election', 'Election_Type_Presidential Primary', 'Election_Type_Primary'.
The dataset can be found here:
Available to the public via Washington Secretary of State, meaning that the dataset may be limiting in accuracy and completeness.
A copy of the python code can be found here:
Data Gathering:
Plan and direct data gathering to opensource repositories (Google). Looking for keywords such as “Voting data”, “Washington State”, “+ .csv”. Next, selecting the 1st to 3rd ranked piece of accessible content and inspecting each csv file for quality such as “length” (at least 7k rows), data cleanliness, massive gaps in data, and enough relevant variables to create an ‘X’ and ‘Y’ axis. In Random Forrest, the dependent variable may be a continuous (interval or ratio) level of measurement or categorical (Statology, 2019). Fortunately, all dependent variables are continuous. The dataset is 0% sparse and all missing or null columns will be dropped when cleaning the dataset. The ‘year’ will be separated from the date in python.
Data Analytics Tools and Techniques: A KDE plot was used to visualize the distribution and visualization graphics were used to test for normality. Random Forrest is germane to studying this data because it can handle distributions of data of non-parametric data. However, the Random Forrest test does not assume normality in the data (Statology, 2019). Overall, this is an exploratory quantitative data analytic technique and a descriptive statistic. The tools used will be Jupyter Notebook operating in Python code, running statsmodel api as a reliable open-source statistical library. For usability, a Pandas data frame will be called, same with Numpy and Seaborn will be used for visualizations. A Random Forrest test will be the statistical test used with sklearn’s RandomForrestReggressor function. A presentation layer with Univariate and by Bivariate graphs will be generated for exploratory analysis.
Justification of Tools/Techniques:
Python will be used for this analysis because of Numpy and Pandas packages that can manipulate large datasets (IBM, 2021). The tools and techniques are common industry practice and have consensus of trust.
The technique is justified through the integer variables necessary to plot against a timeline. In so doing, may just reveal different modes of frequency distribution. Another reason why Random Forrest is ideal is because the data is based off of human voting behavior, which is notoriously skewed. Because of the size of the dataset, pandas and Numpy will be called. Python is being selected over SAS because the Python has better visualizations (Panday, 2022).
Project Outcomes: In order to find statistically significant differences, the proposed end state is a Random Forrest predictive statistical model that can compare the distribution shapes of the targeted groups (Statology,2019). A visualization of the frequency distribution of the voter turnout % against a yearly timeline, indexed at 2007. A cleaned dataset of all the correctly labeled columns and rows, for replication. A better understanding of previously stated groups with exploratory graphs, giving support as to what time engagement maybe highest. Lastly, a copy of the Jupyter NoteBook with the Python code will be available, along with a video presentation added by PowerPoint. According to the same study Random Forrest was instrumental in support for alternative hypothesis, against other categorical variables. (NIH, 2019).

The correlation matrix gives a Person’s Correlation score indicating how correlated two variables.

If you are interested in predicting Washington State’s yearly population growth, then check out this blog here: Washington States Yearly Population Growth





Below is the results for the Random Forrest model to predict voter TurnOut%, year over year, for all elections for the next 10 years. The model is inaccurate and has produced an overfit prediction do to a small sample size. Notice that the TurnOut% does not increase year over year. The output has an R2 score of -0.13 when it should be as close to 1 as possible; Additionally a Mean Squared Error of 748.68, when the MSE should be near ‘0’. These scores lead to accepting the Null Hypothesis that VoterTurn% cannot be predicted because it is random with in a continuous distribution.

Below is the results for the Random Forrest model to predict voter TurnOut%, for General Elections, year over year, for the next 10 years for . The model is inaccurate and has produced an overfit prediction due to a small sample size. Notice that the TurnOut% does not increase year over year. The output has an R2 score of 0.12 when it should be as close to 1 as possible; Additionally a Mean Squared Error of 572.67, when the MSE should be near ‘0’. These scores lead to accepting the Null Hypothesis that VoterTurn% cannot be predicted because it is random with in a continuous distribution.

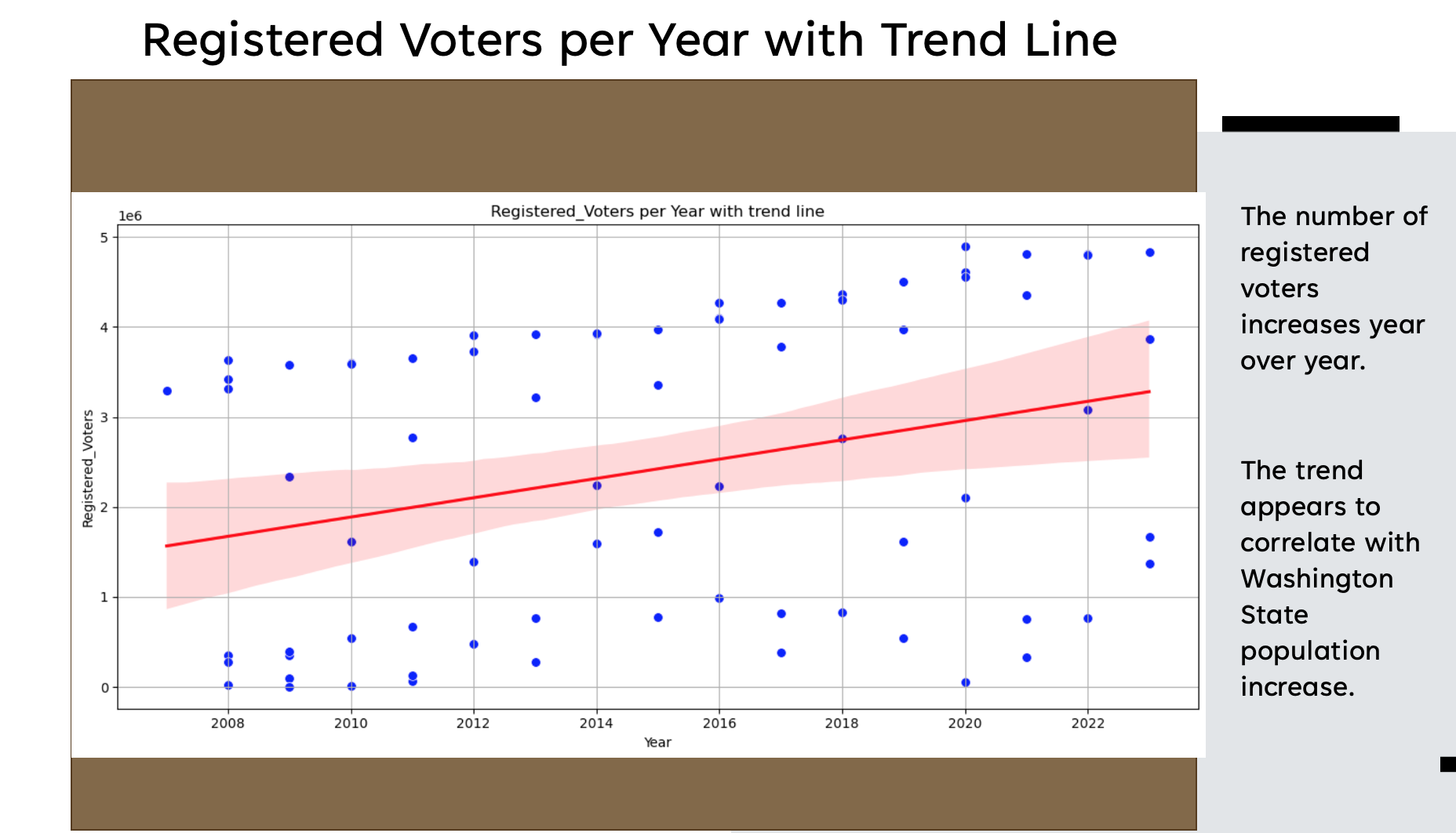
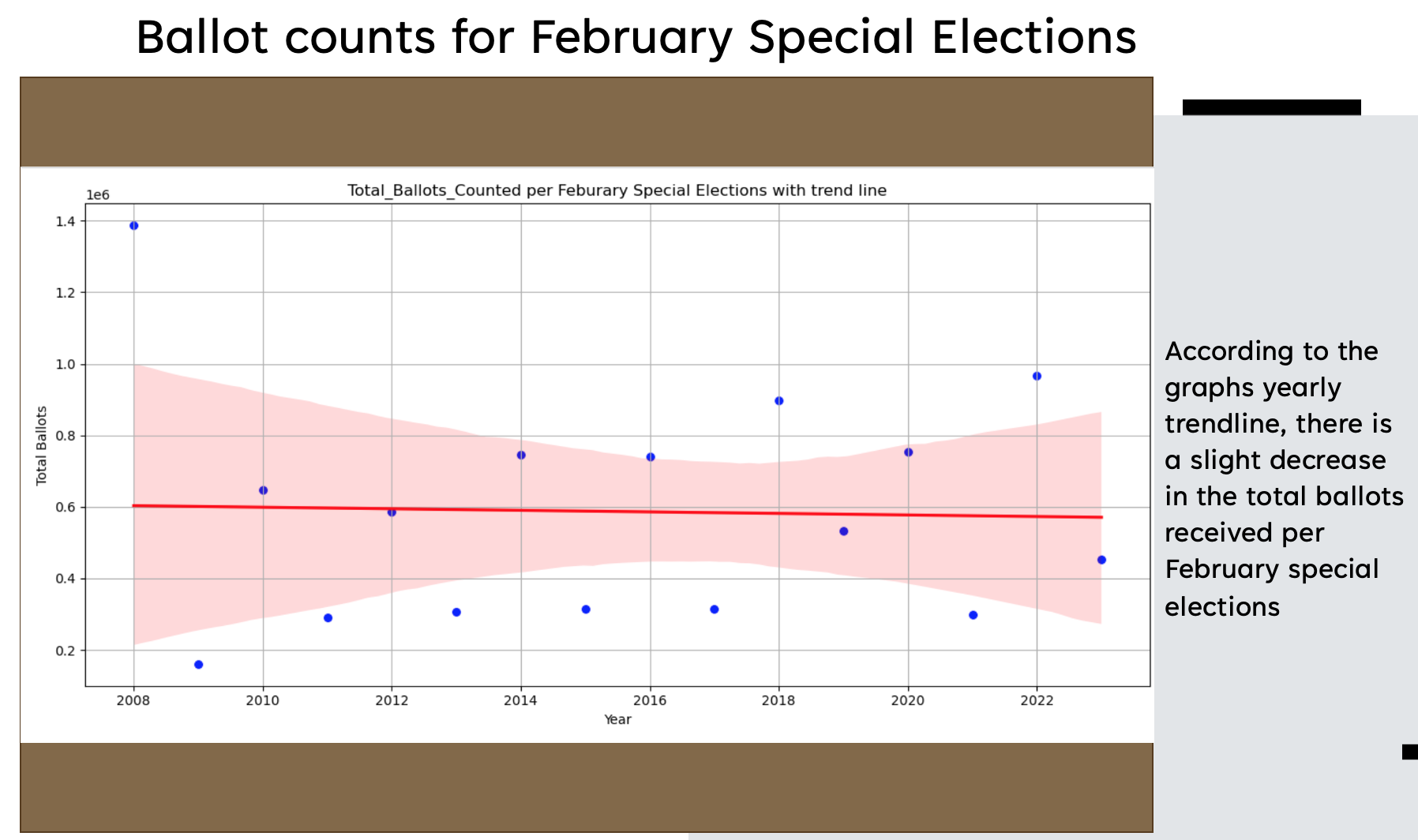
In final analysis, according to the results of the Random Forrest predictive test, we accept the Null hypothesis that Washington State voter behavior is random and not predictable. The result appears to be that of overfitting in the data, meaning that is cannot generalized well on unseen data. Overfitting is most likely the case due to the small size of the dataset to begin with, only 73 rows; Representing all elections from 2007 to 2023. The distribution of voters is a continuous distribution between 0 and 100. The average turnout percentage is highest for General Elections at a constant rate of 52%. However, as the number of registered voters increases, the number of ballots received increased at the same rate. At the same time, the auto generated trend line for the turnout percentage of all elections is decreasing slightly.
Work Cited
Discrete versus continuous probability distributions. Discrete vs Continuous Probability Distributions. (n.d.). https://stattrek.com/probability-distributions/discrete-continuous
Pandey, Y. (2022, May 25). SAS vs python. LinkedIn. https://www.linkedin.com/pulse/sas-vs-python-yuvaraj-pandey
What is Random Forest?. IBM. (2021, October 20). https://www.ibm.com/topics/random-forest
Zach Bobbitt(2021, August 9). A simple introduction to random forests. Statology. https://www.statology.org/random-forests/
Zhang, M., Alvarez, R. M., & Levin, I. (2019, October 31). Election forensics: Using machine learning and synthetic data for possible election anomaly detection. PloS one. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6822750/

Explore more great finds with Data Mining Mike.