

What is Data Mining?

Hello world! I am Data Mining Mike and today we are going to explore the fascinating world of data mining!
Up there in the cloud ☁️ so high;
There’s a bunch of data 📊 on you and I;
So much that nobody knows what to do 🤷♂️;
In streams of data a story unfold;
bytes of data worth more than gold;
But there’s a guy who is on your team 🤝;
Who takes dirty data 🧹 and makes it clean ✨;
And feeds it to the machines 🤖 to inform you!
I’m talking BIG DATA 🌐;
Data that you want and data that you like 👍;
Data that you need, with Data Mining Mike;
And subscribe 📩 as we go on a data mine ⛏️!

We will be covering the following topics:
1. What is Data Mining?
2. Machine Learning basics

In the 1990’s the Walmart Corporation used a machine learning model called Market Basket Analysis to discover that diapers and beer are commonly purchased on Friday nights. Since then all major store chains have changed their layouts and product placement based on this finding.
Data mining is slang for, “data science”.
Data science is a field of study that analyzes big data for predictive, descriptive, diagnostic, and prescriptive solutions.
It is chemistry for data.

Determining the appropriate Machine Learning model(s) based on the underlying assumptions and the data’s probability distribution.




Below is the basic process / kata / flow of data science. It is part of the scientific method.



Data is aggregated from various sources into a master set. The master set is still and unsolved rubrics cube. Data cleaning is solving the rubrics cube. A cleaned dataset is essential for the scientific process and machine learning.


Data Cleaning is the most important process of all Machine Learning
Garbage in = Garbage Out
Once the data is cleaned, each variable distribution needs to bee inspected by visualizing it in a graph.

There are only two categories of variable distributions: Parametric or Non-Parametric.
Determining the distribution of all germane variables is necessary for machine learning because there are only two major groups of machine learning models: Parametric or Non-Parametric.


Who’s got all the best data?


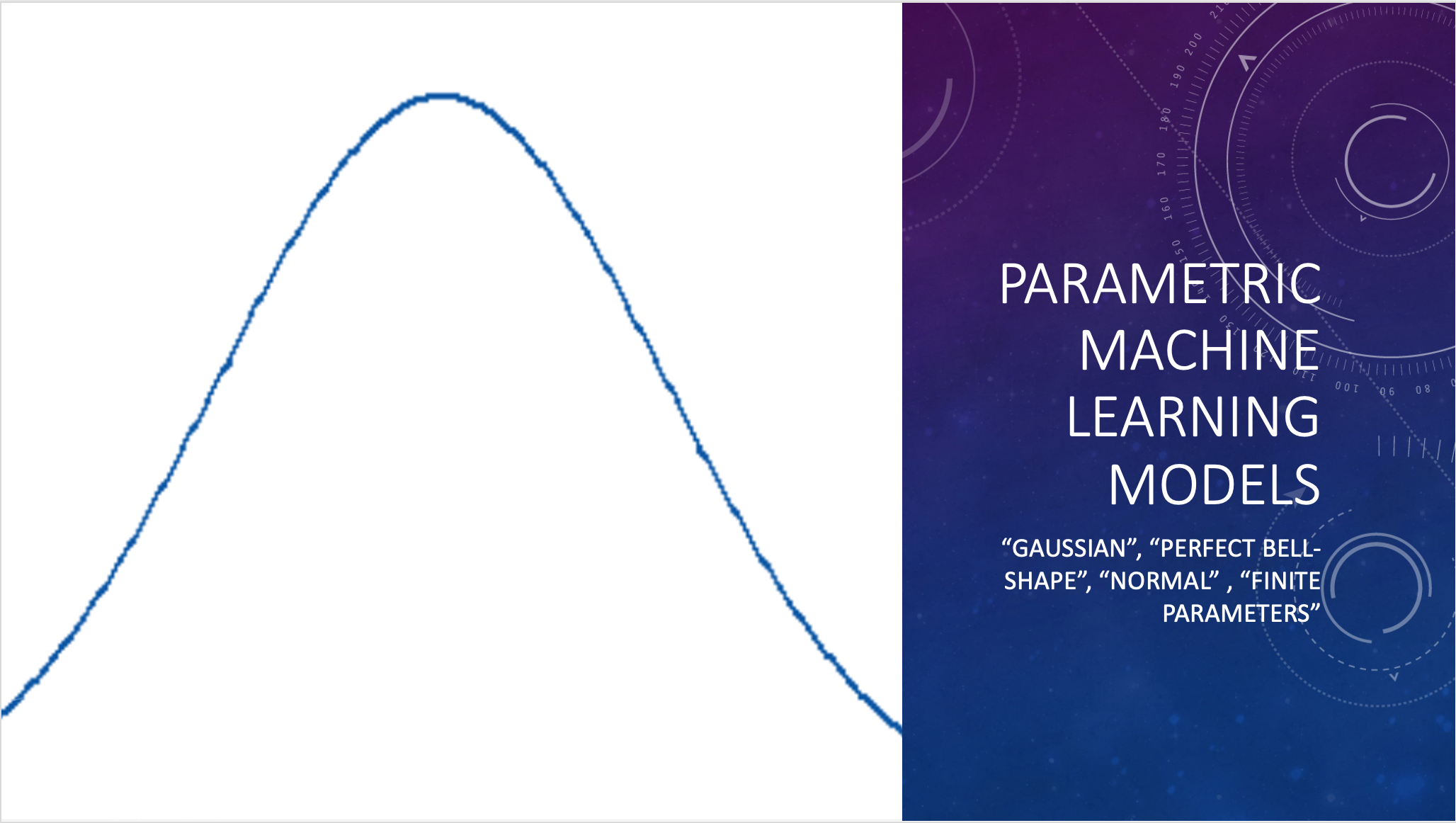
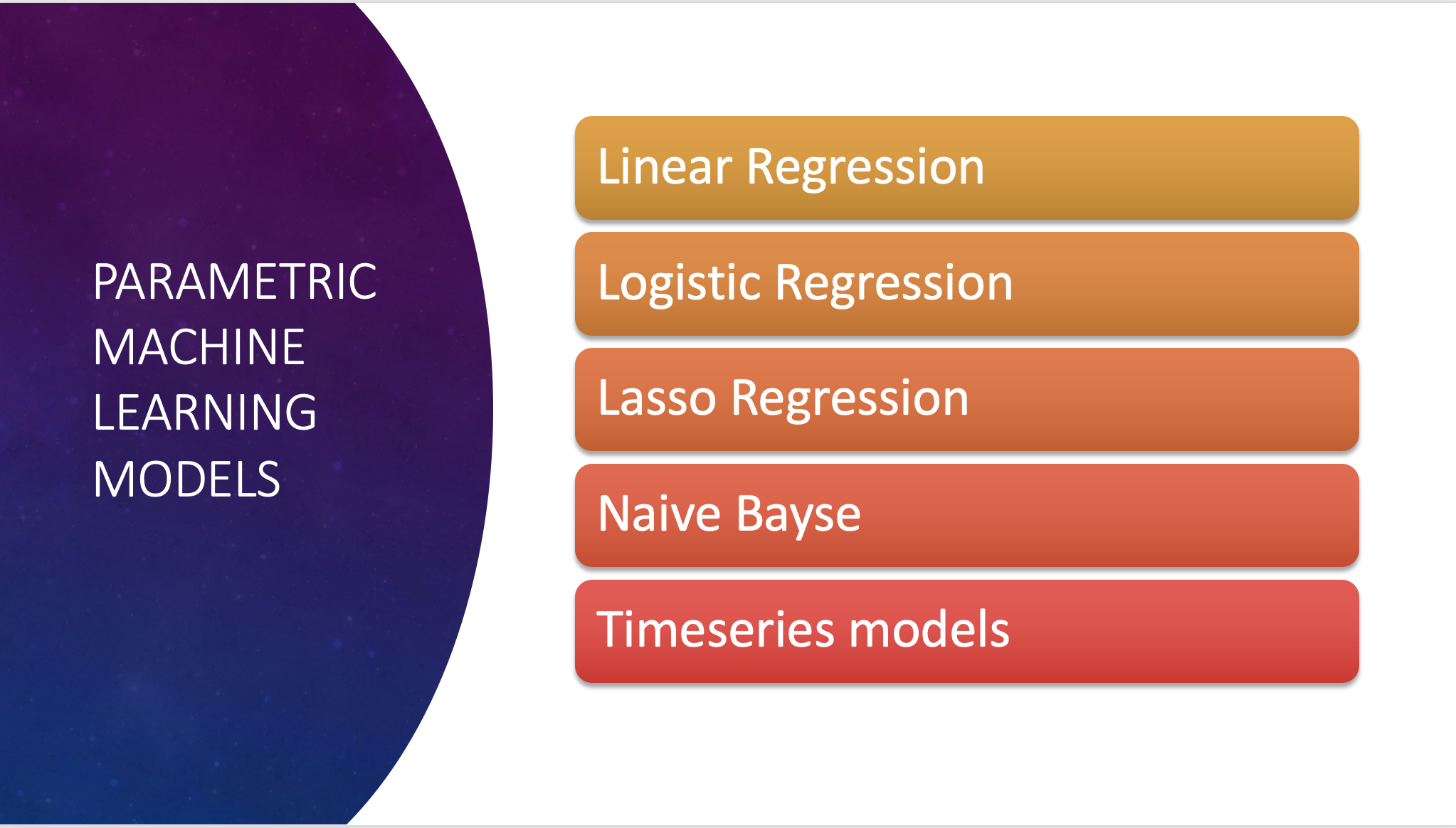
A parametric model assumes a perfect, unskewed, Gaussian, bell-shaped curve.
Non-parametric models are for any distribution that is not a perfect bell-shape.

With in the world of Parametric and Non - Parametric machine learning model, there are two types:
Supervised and Unsupervised machine learning.
The difference is: One is trained on labeled data while the other is not. Supervised machine learning models can get very accurate. While unsupervised allows you to see patterns in the data that humans may not be able to pickup.
Unsupervised machine learning allows you to ‘see like the machines’ with models such as cluster analysis and Market Basket Analysis.



Once the model is trained and optimized on the clean data, it gets deployed to classify or predict something.

Explaining the process without pictures:
Feasibility Study – A scientific research product, prompted by one of two things (preferably both): business question(s) and / or data. Each business question is interrogated along with the data. Generally reducing the business question(s) into one type of question: “What do you want to classify or predict?”. The question is explored starting from the Extract, Transform, and Load phases. Follow on questions such as the data volume, velocity, and End-User purpose are discussed. If the data is provided, then the data will be mined and findings disseminated back in a report for the client. The answer to the business problem(s) may be found in the data or the data may reveal and answer to a bigger industry question(s). Sometimes the data is just random unworkable noise and no human or machine can predict or classify random noise. If possible, during data exploration, certain features may be engineered for additional discovery. When exploring the data, the visualized probability distribution of the Independent and Dependent variables will dictate if a machine learning model(s) can be used. If the variables fit the assumptions of the models, then we explore those models. Initially exploring with unsupervised machine learning, to uncover unseen patterns. Then we isolate Independent Variables attempting to predict or classify using a series of machine learning models. If we can use supervised models (labeled data), we conduct the model training, testing, scoring, and initial optimization. The model scores will be presented in the Feasibility Report, along with all the visualizations, and objective findings in the data. Report also contains a road-map for readiness of the model deployment. It may contain instructions for data pipeline development.
Another way to explain the Feasibility Study, is the world of physical mining for earth elements. Imagine that you work for a physical mining company that mines for ore underground. Clients employ us to mine for elements on the Parodic Table. We can also make robots that can classify or predict the earth elements in the raw ore. Clients come to us with the ore from their land; We inspect the ore, clean / refine, and generate a report of all the elements in the ore. Then we see if we can make an accurate custom robot for the end-user to interact with the ore elements. Sometimes clients send us core samples of quartz, looking specifically for gold. If there is gold, we can find it in the quartz with particular-robots. We can extract, process, and test the gold for purity; We can setup these robots on assembly lines of crushed quartz. We construct and periodically inspect the entire assembly-line for quality assurance. Given the linty of forms to fill-out, The Feasibility Study gives the clients a full-roadmap of how likely this process to work for them as well as a manual for the proper care and operation of the assembly line. The report of the findings will be presented to the client.
Data Mining – Very similar to a Feasibility Study but more fungible to specific questions to be answered by mining data in bulk. The number of total end-users determines the costs for reasons such as: compute time, storage, security, and labor. With generalized data mining, the scope of work is more narrowed to reduce waste. Unlike the Feasibility Study, general data mining requires the data and specific intelligence requirements. Intelligence requirements in the form of specific questions. The questions may vary and are not necessarily reduced. General data mining also produces data products such as leads-list, WordCloud outputs, visualizations, feature engineering, specific model predictions or classifications, and a report of the findings. In some instances, data mining operations will end with an interactive dashboard for the end-user. In other instances, it’s just the generation of leads-lists.
Another example may be to engineer one data set, once, such that Market Basket Analysis can see what the co-occurrences of items purchased are. In some instances, a client may want to forecast revenue or explain a cost. Another example may be exploring what direction a KPI is going. In other cases, it may be to discover unknown patterns in the data using cluster analysis. Maybe a client wants to see the WordCloud, showcasing the word and frequency of key-words in customer reviews or video comments. Maybe a logistics company wants to find the optimal truck-load for a specific client. Maybe a company wants to reverse-engineer itself with its own data. There are numerous combinations of events that can occur in one data mining project. Therefore, defining the scope of work is paramount.
Custom Machine Learning Model Creation, Deployment, and Maintenance -
Starts after the Feasibility Study. Includes a clearly defined question of prediction or classification. Includes that data pipeline development outlined in the Feasibility Study. It includes the creation, training, testing, optimization, and deployment of the model to the end-user information systems. Continued testing and maintenance in the form of reoptimizing the ML model based on new data and other metrics determined.

Learn about more great data mining finds here:
What to do if you get failed for AI content?
Reverse engineer Google Political Ads
Exposing the scandals of patient law
The Washington State Amazon Spending Scandal
What are the odds of winning a government contract?
How many people have died in Tesla fires?
How many solar panels does your house need?
What category is best for YouTube?